Data in the wild
So far in class, our data has mostly come nicely formatted. But in the wild it’s rarely that nice. Today we’ll do one small exercise together and then work on scenario where you get data in a terrible, terrible format.
Housekeeping
• Your pitches and your homework for tomorrow.
• A sample of R code and questions about last class’s exercise. Challenges/excitements.
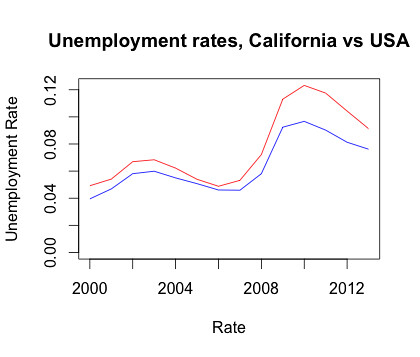
- Erik + Chelsi + Stephen chart code
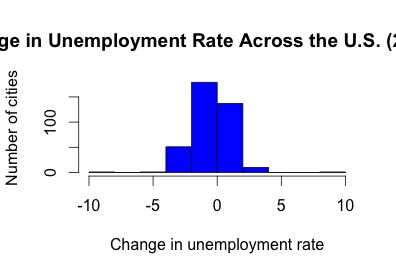
- Aaron chart
- Julie chart code
- Sam code chart
- Sam, Pearly, Nausheen. Sweet! chart + map
{kind=link}
{kind=link}
• Office hours this weekend at 6
• Yet more free help on the wiki
• Possibly handy guide to data transformations
Critique
Sam and Nausheen are discussing a recent UGC map by the Washington Post this week.
Exercise
You’re a data journalist working at the Chicago Tribune’s tribapps team. The city is generally good about making its data public – there’s a data portal that keeps data of every crime, and another news site, RedEye, maintains an app dedicated to tracking homicides in the city. Things were not so good last year – the city had its highest number of homicides in 5 years, which attracted national attention.
In this exercise, you’ve obtained data about successful gun traces in Chicago in the last 10 years. (A gun trace is where they find out where a gun found in a crime was purchased.) Go ahead and download it.
Each row in this data represents a county in the United States and how many Chicago guns were purchased there.
We’ll break into 4 (6 if you count missing people) groups for this.
Group 1: Erik Reyna, Sean Greene (gone for ONA)
Group 2: Jess, Angie, Chelsi (gone for ONA and/or sick)
Group 3: Sam Rolens, Aaron Mendelson, Samantha Masunaga
Group 4: Julie Brown, Diego Barido, Stephen Fisher
Group 5: Mihir Zaveri, Nausheen Husain
Group 6: Pearly Tan, Tawanda Kanhema
We’ll start up together, ask some questions, do some light formatting, then we’re off to the races.
Here’s your rough schedule
Starting at 4:45pm
Download and format the data and load it into R.
As a group, come up with at least 6 questions that you want to answer using a Google doc or raw text file. If you think you might want to use other data files or shapefiles, list them here. If you want county or state map files, someone nice already collected them for you.
Starting at 5:00pm
- Call Shavin over to approve your questions. Don’t continue without approval.
Starting at 5:15pm
Start answering your questions in text form.
Sketch on paper what you want to build with your new knowledge.
Starting at 5:45pm
Get Shavin approval of your sketch before you continue.
Decide who’s doing what. Here’s one idea for roles, but feel free to do whatever you want:
- Research and write the text.
- R sketching and answering data questions.
- Web development of the whole project. (You don’t need to make your chart in D3. Images are fine, but they do need to be published to the internet on a valid HTML page. )
Starting at 6:45pm
Publish a URL to a github repo.
6:30pm and publish a URL to a github repo.
6:45pm We’re all going to share our projects.
Starting at 7:00 (to 7:15?)pm
- Show and tell.
Homework
Same as before – post your sketches online with a link to reproducible R code. In this case, though, make a valid HTML page with a headline, readout, and some body copy (presumably answers to your data questions), and some questions you’d like to pursue if you have time. We’ll post a template or two that might be useful for you, but feel free to make your own, too.