Thinking critically with data
Moving forward.
Housekeeping
• Are you a member of the class Google Group? Are you sure?
• Check out the gallery of bar charts from your assignments
• Common mistakes:
github pages not hooked up correctly
hardcoding values on labels: why it’s good and why it’s dangerous
repeating code
• Office hours
Critique
Mihir and Aaron will be discussing this map of NYC primary results.
Lecture
Lab
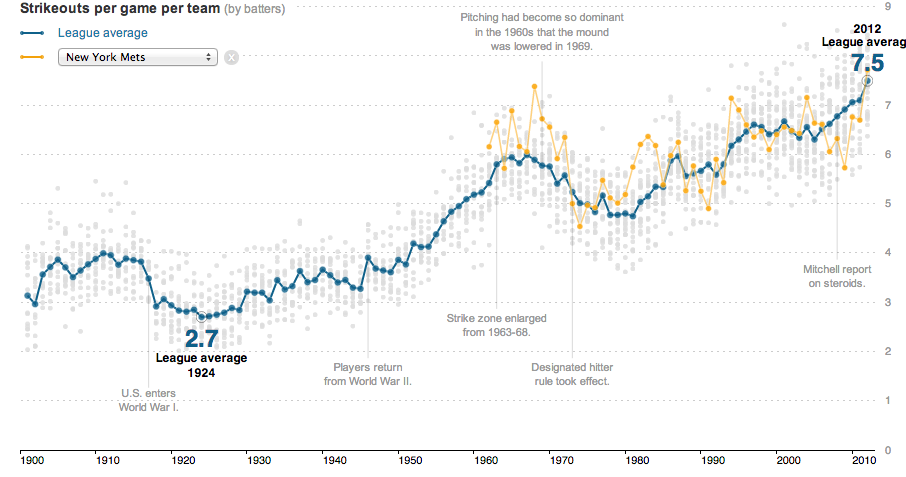
Say you’re a sports reporter covering the Oakland Athletics and you heard one of your sources talk about a shift in the way the game is played. Your source, a batting coach, says he tells his hitters to swing aggressively no matter the pitch count – in the past, he had told them to be more defensive when they had two strikes, opting to put the ball in play rather than strike out. As a result, your source says, players are striking out much more than they used to: last year, the team struck out more than than any time in franchise history.
As a journalist who’s literate with data, what might be a logical way to assess the veracity of this claim and provide insight on this trend to your readers? Where might you get data to prove or disprove this claim?
R
Start a new github repository in your “dataviz-home” folder called “line-chart”. Download this CSV file, which has the strikeouts per team for every team in a franchise’s history, into that folder. Also create a blank R file called
strikeouts.Rand an empty HTML file calledindex.html. (We’ll do this every class, so you should get used to it!)
(By the way, the data comes from baseball-reference.com, one of the best sites on the internet for sports data. Sometimes you have to scrape it, but frequently it’s available to download.)
Open
strikeouts.Rin a text editor of your choosing. You can either cut and paste between your text editor and RStudio or just code in RStudio, but do have a place for your working code somewhere.In this public Google Doc, write down some questions we should ask our data.
Open RStudio or the R console, whichever you prefer. Load the data and check it out.
setwd("~/dataviz-fall-2013/line-chart") strikeouts <- read.csv("strikeouts.csv") head(strikeouts)What does our data look like? What do the rows represent? What do the fields represent?
We have fields for strikeouts and fields for games, but there have been varying season lengths throughout the year. How many different season lengths have there been? Here’s some code that might be useful for this (and later):
unique(strikeouts$g)Why might there be so many different values?
Let’s normalize this data by making a field called
kpg, for strikeouts per game.strikeouts$kpg <- strikeouts$so / strikeouts$gWhat is the max and min of this vector?
One of R’s most useful methods is called
subset. Let’s use it to return the whole row where there were the most strikeouts per game.subset(strikeouts, kpg == max(strikeouts$kpg))When was it, and which team?
subsetis one of R’s most useful functions. Make a variable calledoaklandthat just has the Athletics' strikeouts. Sort this by strikeouts per game, in descending order.oakland <- subset(strikeouts, franchise == "OAK") oakland <- oakland[order(oakland$kpg, decreasing=T),]Is the batting coach’s claim true?
With filtering (subset) and sorting, we should be able to answer lots of good questions about the data. Let’s spend some time answering questions from the Google doc.
Now let’s make some sketches. First, let’s use our
oaklanddata frame to see if there’s been a trend over time.plot(oakland$year, oakland$kpg)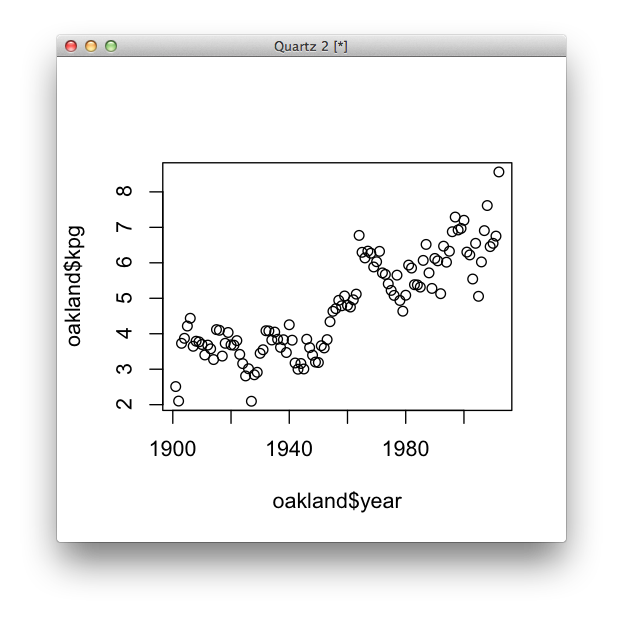
Already we’re seeing something there. What observations can we make, and what new questions might we have for further reporting?
Just to reinforce that
plothas a lot of arguments that can make things a little cleaner for you, try this, which just cleans up the code and adds titles and axis labels. (You can learn more about plot by typing?plotin your R console.)plot(oakland$year, oakland$kpg, pch=16, col="red", main="Strikeouts per game: A's", xlab="Year", ylab="Ks per game", ylim=c(0, max(oakland$kpg)))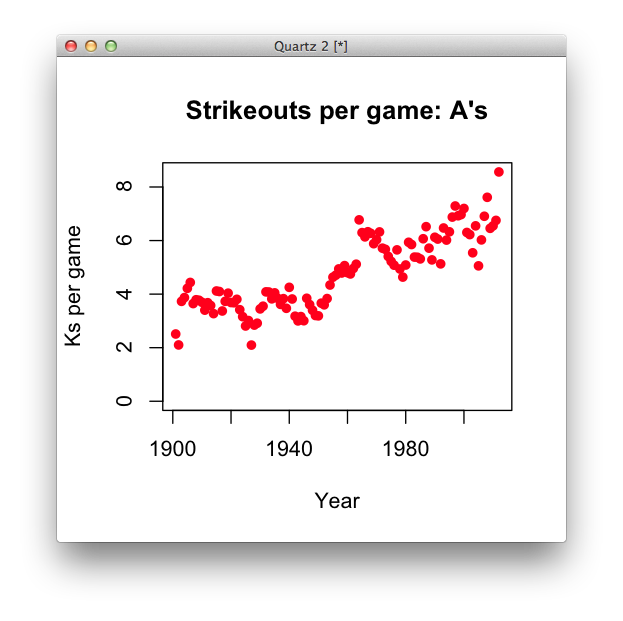
Is zero-basing this chart the right thing to do?
Let’s try the same plot command but with a different type of plot. We’ll also lose the zero-basing.
plot(oakland$year, oakland$kpg, pch=16, col="red", main="Strikeouts per game: A's", xlab="Year", ylab="Ks per game", type="l", lwd=2)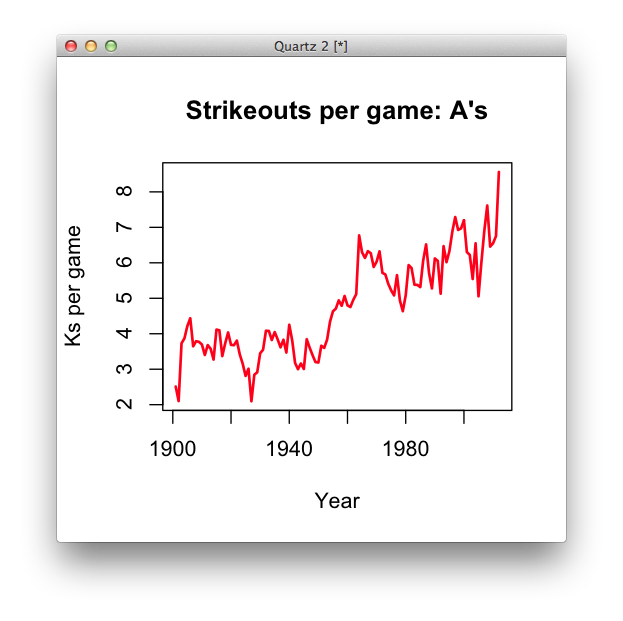
What, if any, merits does this type of chart bring? Which is better?
Clearly we can see a trend of increasing strikeouts per game, but it’s hard for us to know whether this trend is only for Oakland or if it’s something that every team in the league experienced. What would we need to know whether how to characterize Oakland?
Let’s compare Oakland to another baseball team – say, the Minnesota Twins. Make a new data frame just like you did for Oakland:
min <- subset(strikeouts, franchise == "MIN")Now make a similar scatterplot for Minnesota like you did for Oakland:
plot(min$year, min$kpg, pch=16, col="blue", main="Strikeouts per game: Minnesota", xlab="Year", ylab="Ks per game", ylim=c(0, max(min$kpg)))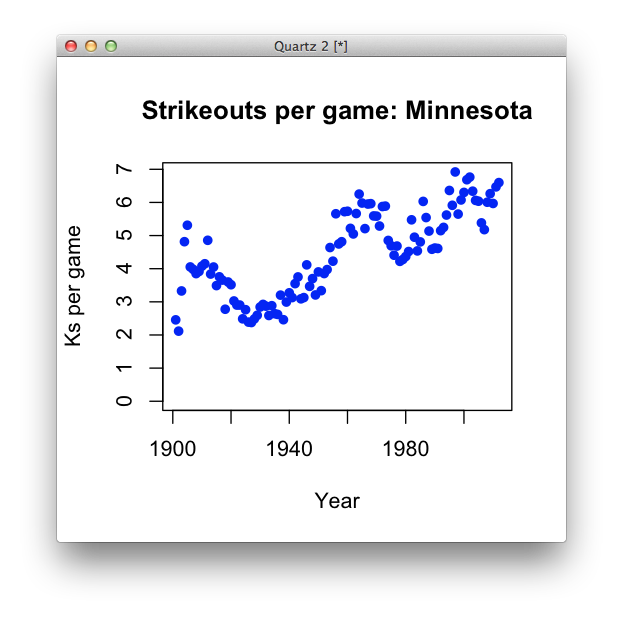
Let’s add the Oakland data on top of this. To do this in R, if you have already created a plot, you use a method called
points. This adds a scatterplot on top of an existing plot.#first, the oakland scatterplot (with a new title) plot(oakland$year, oakland$kpg, pch=16, col="red", main="Oakland vs Minnesota", xlab="Year", ylab="Ks per game", ylim=c(0, max(oakland$kpg))) # now add the minnesota scatterplot. # note the considerably fewer arguments points(min$year, min$kpg, pch=16, col="blue")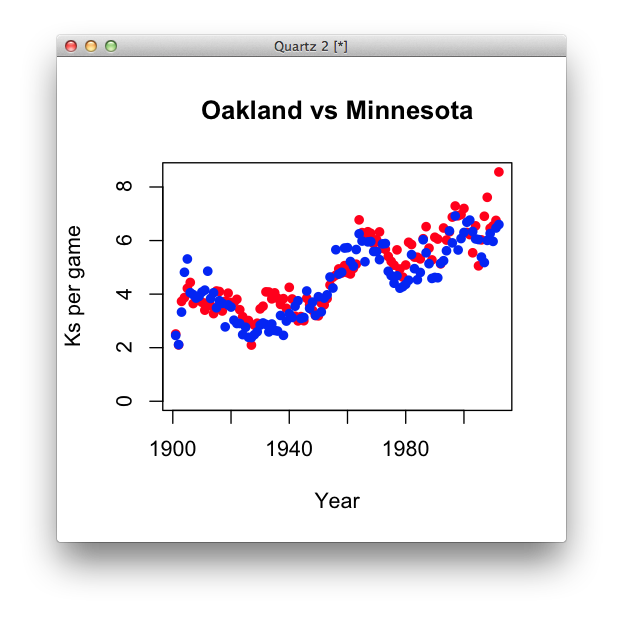
Why are there so many fewer arguments with
points? Also, what troubles might we get into by setting the x and y limits the way we did?More importantly, is it easy to compare these values using this form?
This is where line charts are handy – to compare two or more time series. Let’s do a very similar set of plots, but using line charts instead of scatterplots. Note the differences in syntax. We’ll also be more defensive about setting our “`ylim.
#which is bigger, oakland or Minnesota's max KPG? max_kpg <- max(c(max(oakland$kpg), min$kpg)) #oakland line chart plot(oakland$year, oakland$kpg, col="red", main="Oakland vs Minnesota", xlab="Year", ylab="Ks per game", ylim=c(0, max_kpg), type="l", lwd=2) # minnesota line. lines(min$year, min$kpg, col="blue", lwd=2)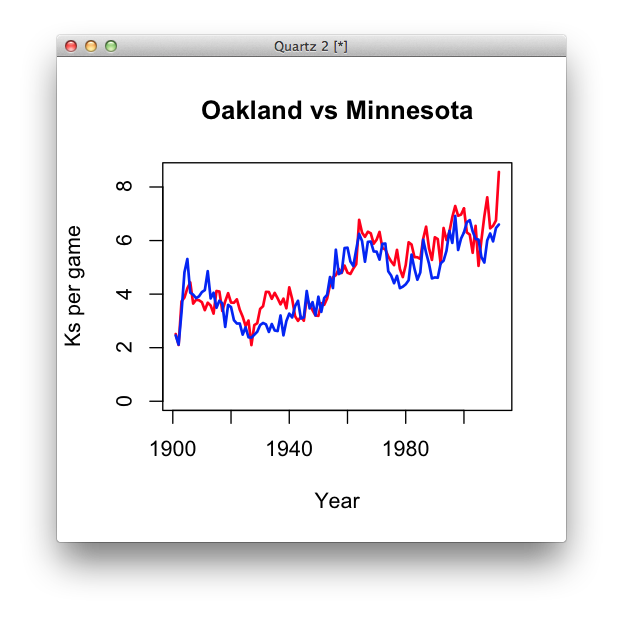
How does this form compare for comparing the two teams?
With this chart, we know the trend of increasing strikeouts per game happened for both Minnesota and Oakland. But to be sure that it’s a leaguewide trend, we need to learn a new and very powerful R method:
aggregate. For those of you familar with Excel, it’s basically the same as a Pivot Table; for those of you who have worked with SQL, it’s the same as aGROUP BYquery. Take a look at the documentation for aggregate by typing?aggregatein the R console.Make a new data frame called
league_average.league_average <- aggregate(strikeouts$kpg, list(strikeouts$year), mean)Rename the field names something normal.
names(league_average) <- c("year", "meankpg")Now let’s take a look at a line chart of league average:
plot(league_average$year, league_average$meankpg, col="orange", main="MLB mean strikeouts per game", xlab="Year", ylab="Ks per game", type="l", lwd=2)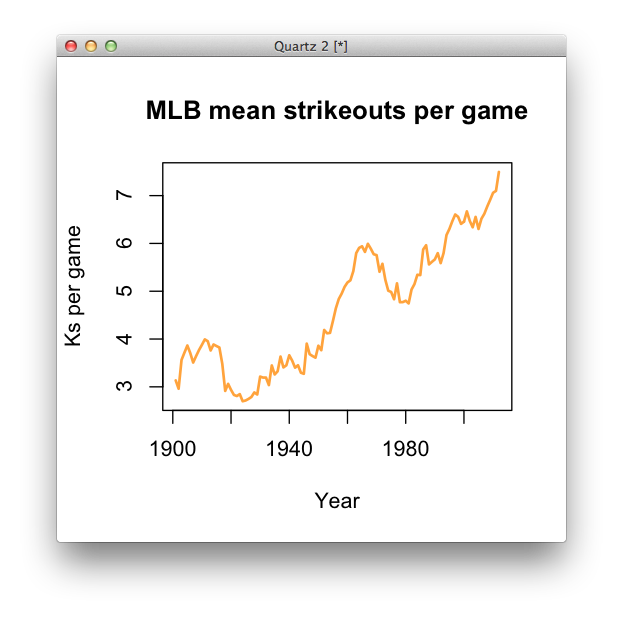
Now the trends are even more pronounced. What new reporting lines might we now have that we didn’t have before we saw this chart?
Let’s compare Oakland to the league average:
plot(league_average$year, league_average$meankpg, col="grey", main="Oakland vs league average", xlab="Year", ylab="Ks per game", type="l", lwd=2, ylim=c(0, max(oakland$kpg))) lines(oakland$year, oakland$kpg, col="red", lwd=2)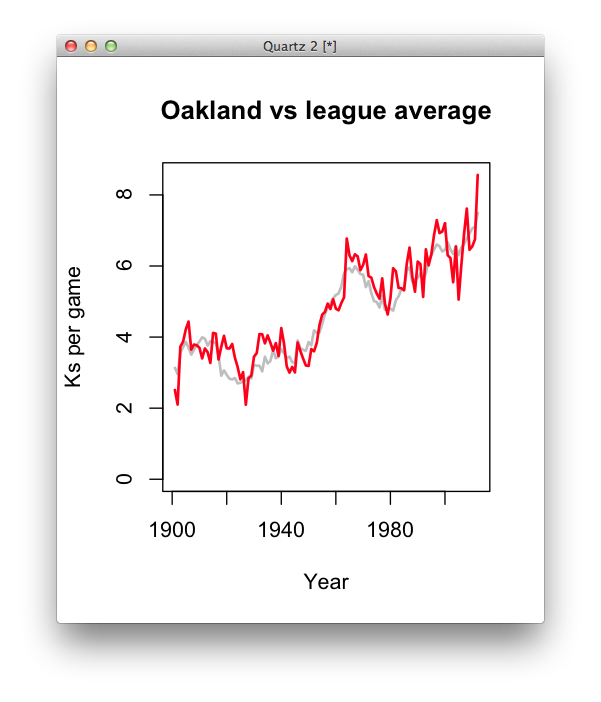
Oakland clearly had more strikeouts than the league average in 2012. What might be some other ways we might look at this data other than as a trend over time? What other data sets might be useful to help readers understand not just what is happening, but why?
With some small cleanup, this chart would absolutely be good enough to provide evidence toward the batting coach’s claim. To make this point, the chart does not need to be interactive. However, what if you want this chart to be useful for any fan, not just readers from Oakland? Or, put another way, this chart is on the web, but if we want it to be of the web, we might want to use something like D3.
D3
Hopefully you already have a line-chart repo with a gh-pages branch setup and have create an index.html file that is based on Scott Murray’s d3 starter. If not, do all that now or ask a friend to help.
First thing’s first. Let’s create a place for our CSS, a headline for our page and an empty container for our shiny chart. We’ll also need a
scripttag for all our fancy javascript.<style> /* Our css will go here */ </style> <h1>Strikeouts on the Rise</h1> <p>Meaningful intro sentence here.</p> <div class="chart"></div> <script> // Our javascript code will go here </script>You should already have your
strikeouts.csvfile in your repo, so let’s try to load it up.d3.csv("strikeouts.csv", function(data){ console.log(data); });Now, some of our number fields are coming through as strings, so let’s fix that. Your javascript should look like this. Now the number fields should look like numbers in the console.
d3.csv("strikeouts.csv", function(data){ data.forEach(function(d) { d.so = +d.so; d.year = +d.year; d.g = +d.g; //We also want to calculate the strikeouts per game and store it as a new column d.kpg = d.so / d.g; }); console.log(data); });We’ll start by making a scatterplot, for which we’ll need two scales. First we need svg element to put our chart into.
var svg = d3.select(".chart") .append("svg") .attr("width", 900) .attr("height", 500);Now we’ll need an
xScale…var xScale = d3.scale.linear() .domain([1900, 2012]) .range([0, width]);And now the
yScale…var yScale = d3.scale.linear() .domain([0, 100]) .range([0, height]);And now for the magical data join
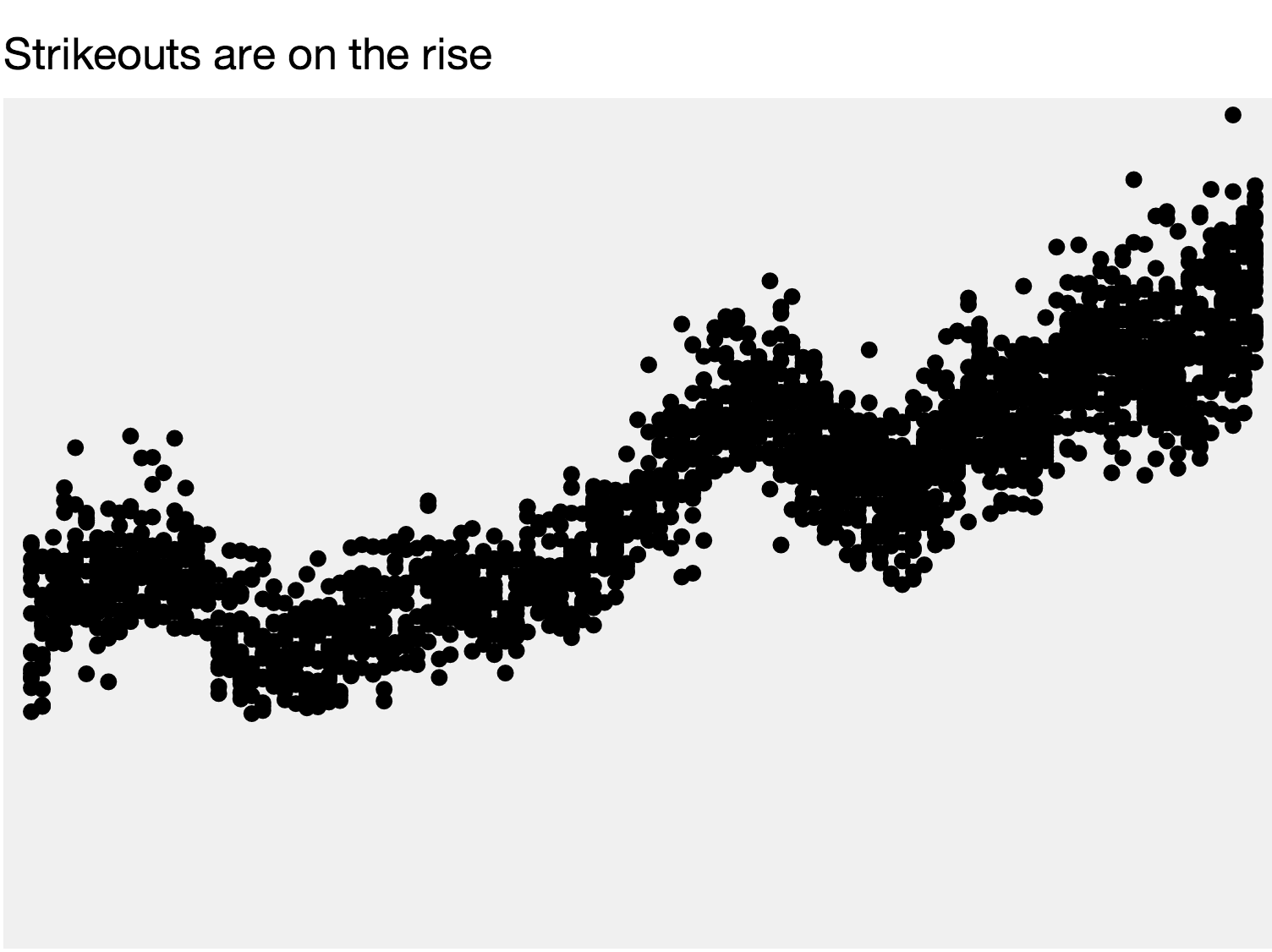
svg.selectAll(".dot") .data(data) .enter().append("circle") .attr("class", "dot") .attr("r", 5) .attr("cx", function(d, i) { return xScale(d.year); }) .attr("cy", function(d) { return yScale(d.kpg); })You should see something like this:

Not great, but a start. Let’s fix our
yScaleso our data fits better and so it’s pointed the right way.var yScale = d3.scale.linear() .domain([0, 10]) .range([height, 0]);Here we’ve switched the range values and hardcoded a better max for our domain. If you want to get fancy, we can calculate that max value with:
.domain([0, d3.max(data, function(d) { return d.kpg; })])but that is optional. Either way, it should look something like this:
Try reducing the
"r"attribute of your circles to2and see what happens.Right now we’re showing all teams for all years, so let’s now filter our data and just show Oakland. Here’s how to show New York Yankees, modify it to show Oakland A’s.
var nyData = data.filter(function(d) { return d.franchise === "NYY"; });Here we’re creating a new data variable
nyDataso we also need to make sure our data join is using this variable and notdata.svg.selectAll(".dot") .data(nyData) //...You should now only see the dots for Oakland.
The title of this lesson is "line chart” not “scatterplot” so let’s get at least one line in there.
The weird thing about svg is that a complicated line is actually one element — as opposed to the circles where there is a circle element for each data value. For a line there will be only one element for ALL our data values.
So, first thing we need to do is create something that is called a
d3.svg.line()generator.var line = d3.svg.line() .x(function(d) { return xScale(d.year); }) .y(function(d) { return yScale(d.kpg); });This creates a function for us that we are saving as
lineand this function will take a data set and spit out the proper code to make an svg path element. Here’s how we use it:svg.append("path") .attr("d", line(nyData));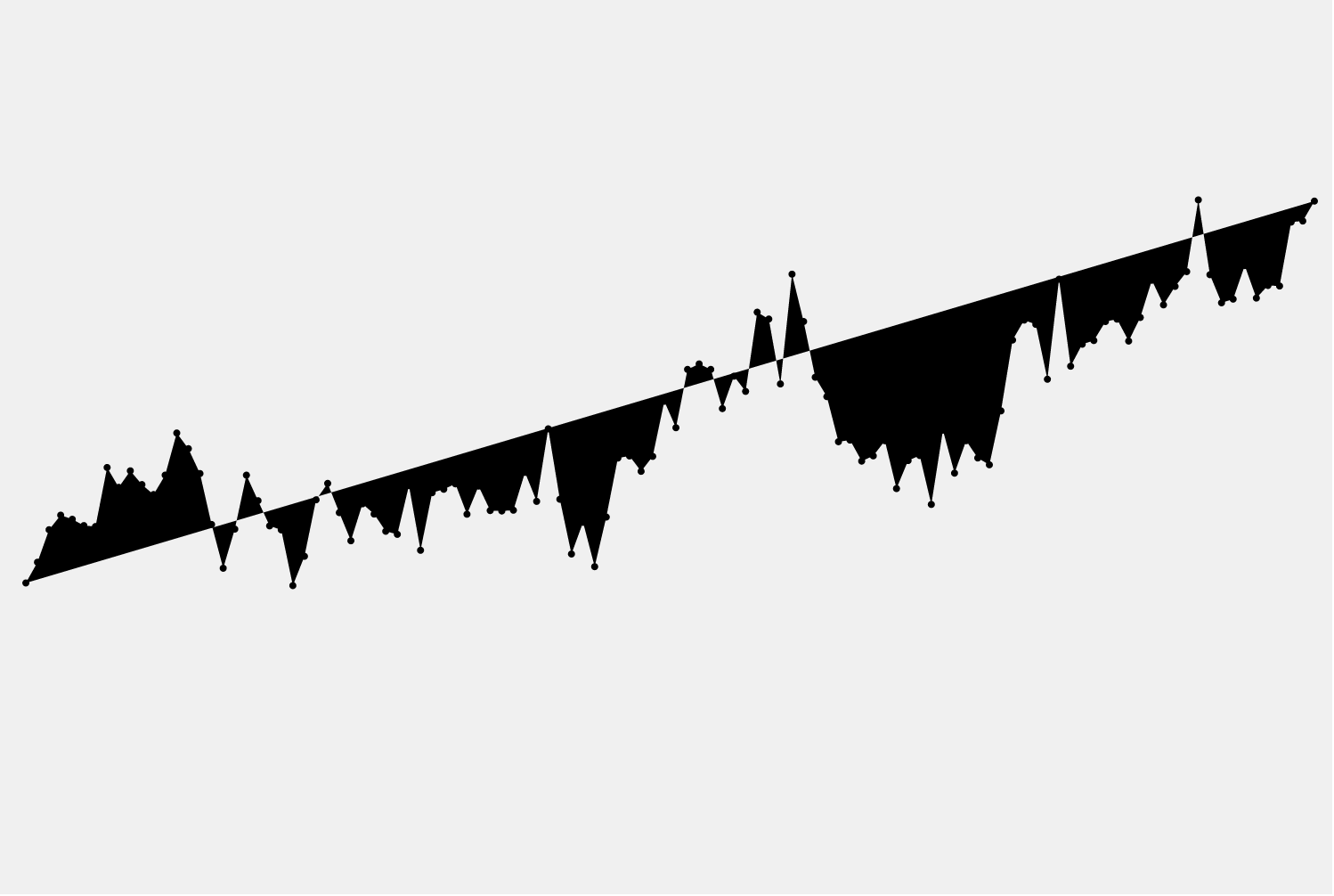
What this is doing is creating a
pathsvg element and adding thedattribute with all our magic line code. Unfortunately it looks a little funky because it has a fill and no stroke, so let’s fix that with CSS.Add this CSS style rule to the
stylearea of your page and add a class to the path elementjavascript svg.append("path") .attr("class", "line") .attr("d", line(nyData));<style> .line { fill: none; stroke: magenta; } </style>We should probably start labeling some stuff now. Let’s start with an axis.
Similar to the line generator, we need to now create an axis generator (which won’t actually create an axis, only create the function to create an axis. Mind blown.)
var xAxis = d3.svg.axis() .scale(xScale);Now, let’s use this generator to generate some svg code.
svg.append("g") .attr("class", "axis") .call(xAxis);The axis should show up, but it’ll look super janky and be on the top of the page and the numbers are weird and it get’s cut off. Let’s tackle these one at a time.
The D3 margin convention is there to help with the cutoff problem. We cut some corners and just appended an svg element at the start instead of setting things up proper, so let’s take a step back. Up where we appended our “svg”, let’s replace it with this code:
var margin = {top: 20, right: 20, bottom: 20, left: 20}; width = 750 - margin.left - margin.right, height = 500 - margin.top - margin.bottom; var svg = d3.select(".chart").append("svg") .attr("width", width + margin.left + margin.right) .attr("height", height + margin.top + margin.bottom) .append("g") .attr("transform", "translate(" + margin.left + "," + margin.top + ")");You should now be able to see your entire axis text.
Let’s move the axis to the bottom of the page. Right now it’s in a
gelement, which is a group, so we can just move that around. Unfortunately you can’t just use x and y. Instead you have to use a “transform”svg.append("g") .attr("class", "axis") .attr("transform", "translate(0, " + height + ")") .call(xAxis)Next on our list, the labels have weird commas in them, which would be nice if they were numbers, sadly ours are years. D3 is formatting our numbers for us, but we need to override that.
var xAxis = d3.svg.axis() .tickFormat(function(d) { return d; }) .scale(xScale);The rest of our fixes can be made with CSS. Inspect element on the axis component and see what’s what. Inside there should be a bunch of
gelements with.tickclasses and one.domainelement. First, let’s style the.domainelement..domain { fill: none; stroke: cyan; }Now, let’s make those ticks show up.
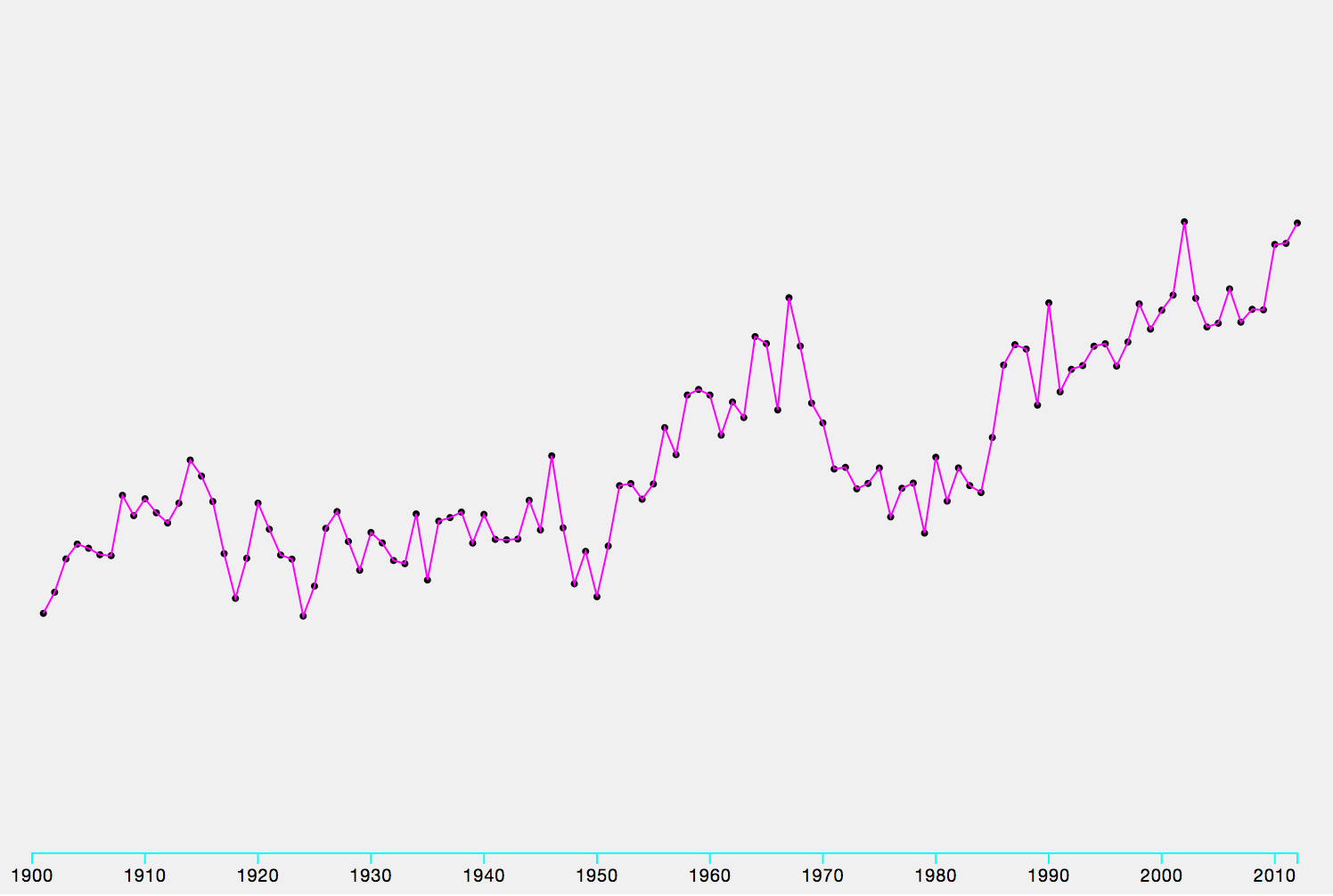
.tick line { stroke: cyan; }And let’s make the text size a little smaller
.tick { font-size: 10px; }You should now have something like this:
Final step, bring some fun. (just copy and paste this into your code)
d3.select(".chart").append("button").text("Blamo!").on("click", function() { d3.selectAll("circle") .transition() .duration(2000) .ease("bounce") .delay(function(d, i){ return i * 50}) .attr("cy", height) .attr("r", 7); });Here’s a link to a working version: d3-line-chart.html
Homework
Your assignment is to publish a line chart with this data in D3 of your favorite team. It’s due Tuesday at noon. It doesn’t have to look like the NYT version, but it might help you figure out some of the code (or not - it is pretty complex):
As we’ve said, grading isn’t the most important thing in the world to us, but here are our expectations.
Requirements
It must be published on its own github branch and linked to from your dataviz-home page.
It must have a line representing the average strikeouts per game of a team of your choosing, along with a title and an X and Y axis.
It must have at least one meaningful annotation describing any trends or insights. Some are on the NYT version already, we know, so try to annotate the line for your team.
For a gold star
Try to have a select element or search box that lets you choose from any team in the league (if we don’t do this in class) and the line redraws based on your selection.
Add a line for the league average calculated using d3.nest()
Add another chart and copy that tells a more specific story, or do more reporting based on data analysis you’ve done here.
Clean up the design of your chart using CSS based on successful line charts you’ve seen in the wild. There are lots of examples.